Abstract
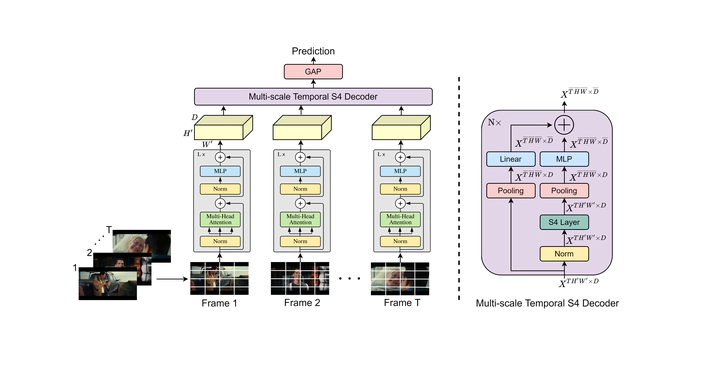
Most modern video recognition models are designed to operate on short video clips (e.g., 5-10s in length). Because of this, it is challenging to apply such models to long movie understanding tasks, which typically require sophisticated long-range temporal reasoning capabilities. The recently introduced video transformers partially address this issue by using long-range temporal self-attention. However, due to the quadratic cost of self-attention, such models are often costly and impractical to use. Instead, we propose ViS4mer, an efficient long-range video model that combines the strengths of self-attention and the recently introduced structured state-space sequence (S4) layer. Our model uses a standard Transformer encoder for short-range spatiotemporal feature extraction, and a multi-scale temporal S4 decoder for subsequent long-range temporal reasoning. By progressively reducing the spatiotemporal feature resolution and channel dimension at each decoder layer, ViS4mer learns complex long-range spatiotemporal dependencies in a video. Furthermore, ViS4mer is 2.63× faster and requires 8× less GPU memory than the corresponding pure self-attention-based model. Additionally, ViS4mer achieves state-of-the-art results in 7 out of 9 long-form movie video classification tasks on the LVU benchmark. Furthermore, we also show that our approach successfully generalizes to other domains, achieving competitive results on the Breakfast and the COIN procedural activity datasets. The code will be made publicly available.
Mohaiminul Islam
PhD Student UNC Chapel Hill Research Scientist Intern Meta AI
My research interests include computer vision, video understanding, and multi-modal deep learning.