Abstract
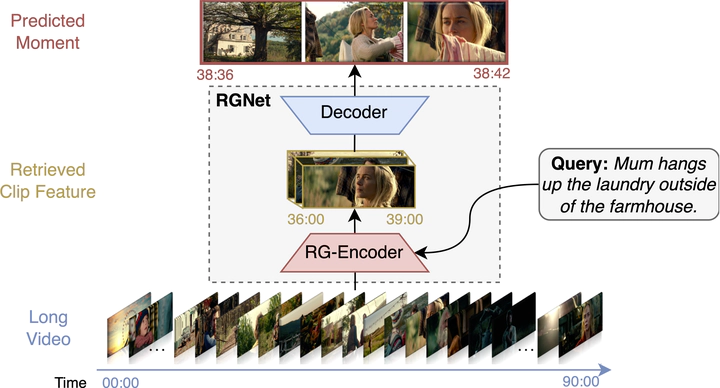
Locating specific moments within long videos (20-120 minutes) presents a significant challenge, akin to finding a needle in a haystack. Adapting existing short video (5-30 seconds) grounding methods to this problem yields poor performance. Since most real life videos, such as those on YouTube and AR/VR, are lengthy, addressing this issue is crucial. Existing methods typically operate in two stages- clip retrieval and grounding. However, this disjoint process limits the retrieval module’s fine-grained event understanding, crucial for specific moment detection. We propose RGNet which deeply integrates clip retrieval and grounding into a single network capable of processing long videos into multiple granular levels, e.g., clips and frames. Its core component is a novel transformer encoder, RG-Encoder, that unifies the two stages through shared features and mutual optimization. The encoder incorporates a sparse attention mechanism and an attention loss to model both granularity jointly. Moreover, we introduce a contrastive clip sampling technique to mimic the long video paradigm closely during training. RGNet surpasses prior methods, showcasing state-of-the-art performance on long video temporal grounding (LVTG) datasets MAD and Ego4D.
Mohaiminul Islam
PhD Student UNC Chapel Hill Research Scientist Intern Meta AI
My research interests include computer vision, video understanding, and multi-modal deep learning.