Abstract
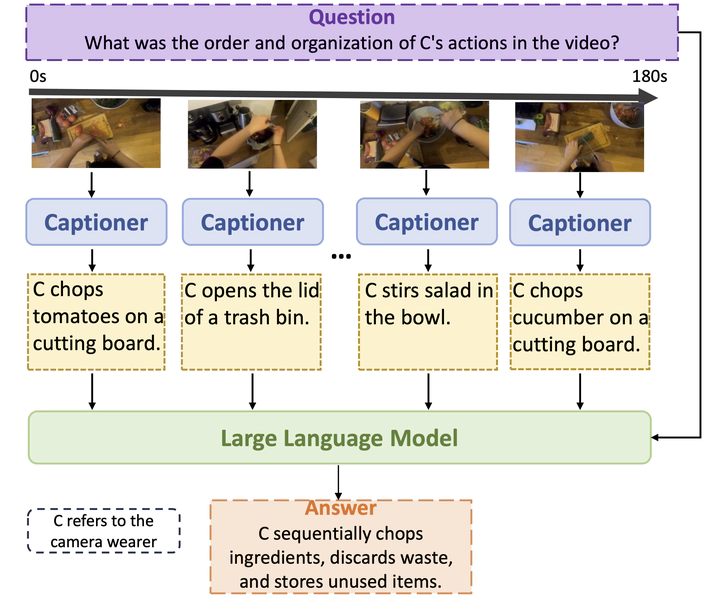
We present LLoVi, a simple yet effective Language-based Long-range Video question- answering (LVQA) framework. Our method decomposes short and long-range modeling aspects of LVQA into two stages. First, we use a short-term visual captioner to generate textual descriptions of short video clips (0.5- 8s in length) densely sampled from a long in- put video. Afterward, an LLM aggregates the densely extracted short-term captions to answer a given question. Furthermore, we propose a novel multi-round summarization prompt that asks the LLM first to summarize the noisy short-term visual captions and then answer a given input question. To analyze what makes our simple framework so effective, we thor- oughly evaluate various components of our framework. Our empirical analysis reveals that the choice of the visual captioner and LLM is critical for good LVQA performance. The proposed multi-round summarization prompt also leads to a significant LVQA performance boost. Our method achieves the best-reported results on the EgoSchema dataset, best known for very long-form video question-answering. LLoVi also outperforms the previous state-of- the-art by 4.1% and 3.1% on NExT-QA and In- tentQA. Finally, we extend LLoVi to grounded VideoQA which requires both QA and tempo- ral localization, and show that it outperforms all prior methods on NExT-GQA.
Mohaiminul Islam
PhD Student UNC Chapel Hill Research Scientist Intern Meta AI
My research interests include computer vision, video understanding, and multi-modal deep learning.